Kubernetes Architecture: Designing for Scale, Speed, and Security
DevOps
– 5 Min Read
Most teams adopt Kubernetes, get a few services running, and only later face the harder problem: which Kubernetes features to wire in, so the platform supports production speed, on‑demand scale, and a defensible security posture. Copying every “best practice” checklist wastes time and adds toil; pick the controls that match your workloads and maturity.
This guide explains which Kubernetes architecture choices matter when you need an enterprise-grade platform. But more importantly, it helps you determine which patterns an organization actually needs, when to implement them, and what trade-offs to expect. Not every organization needs every pattern and understanding your specific challenges determines the right architecture. We move ahead in the order teams usually mature: first tighten deployments for speed, then make scaling decisions driven by real metrics for scale, and finally layer security controls once growth increases blast radius.
Let’s get started with speed first:
Container deployment at enterprise scale on Kubernetes takes more than just manifests. Speed comes from combining trusted artifacts, rollout control, and metric-driven progression to production. To achieve this, we replace Kubernetes default rolling updates with canary deployments, where each new release is tested with a small portion of production traffic before being fully deployed.
Traditional Kubernetes rolling updates replace pods sequentially. If a new version has issues, you might discover them after replacing all the pods. So, we first convert Kubernetes rolling updates to Canary releases. Canary deployments test new versions with limited traffic first, watch key metrics, and either promote or roll back before full replacement. The progression typically follows:
To scale canary analysis for speed, we automate it in Kubernetes with Flagger. Flagger automates this progression. First, install Flagger and configure it to work with your ingress:
kubectl apply -k github.com/fluxcd/flagger/kustomize/kubernetes
Define how Flagger should manage deployments:
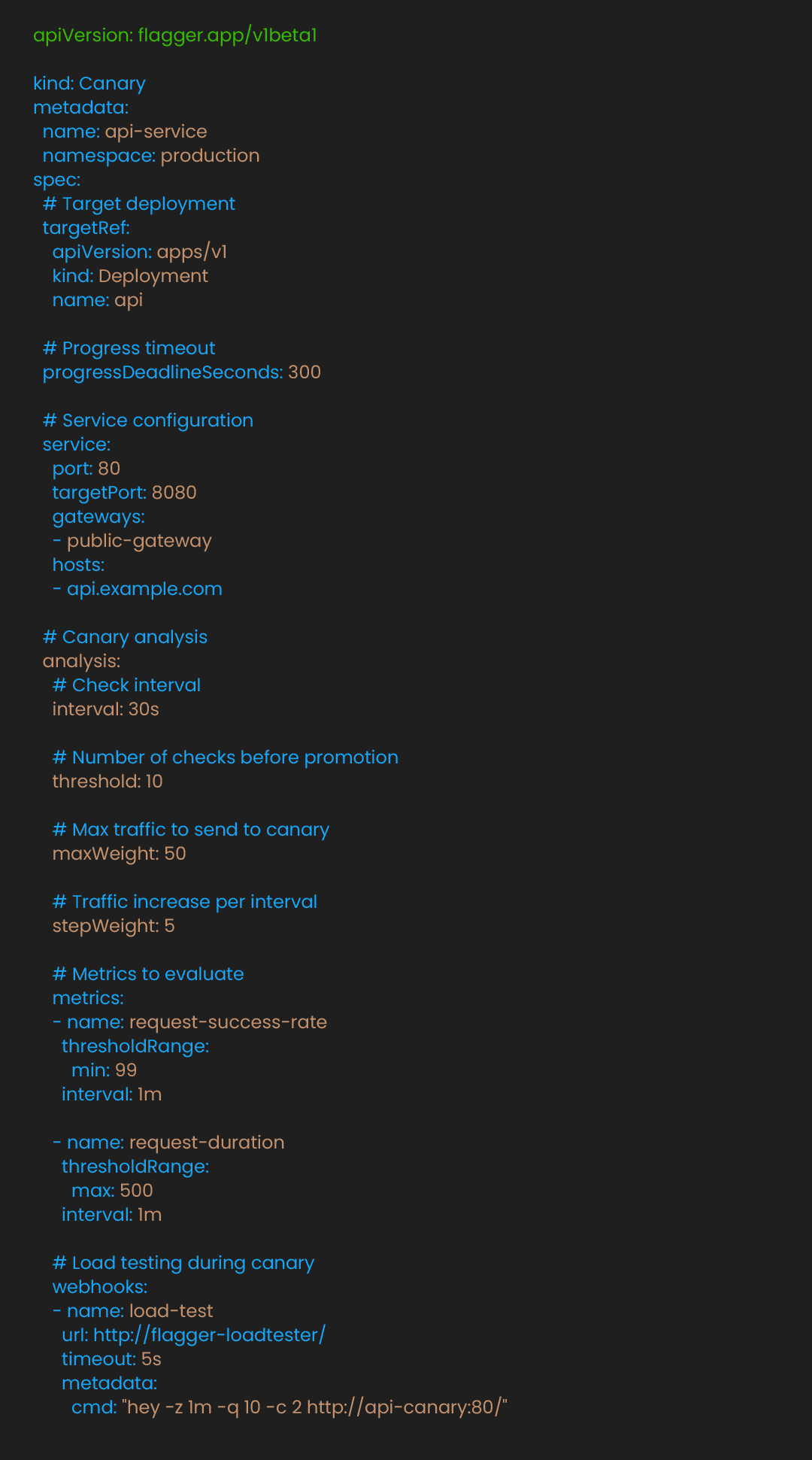
This configuration orchestrates careful rollout. Flagger shifts traffic incrementally while monitoring success rates and latency. If metrics fall below thresholds, it triggers automatic rollback. The webhook runs load tests against the canary, helping identify performance issues before they impact users.
Git-driven ops keep clusters declarative, wiring Flagger into ArgoCD carriers speeds from commit to cluster. Combining Flagger with ArgoCD creates an automated deployment pipeline. The developer pushes code, ArgoCD deploys it, and Flagger validates it progressively. Failed deployments rollback automatically without manual intervention:
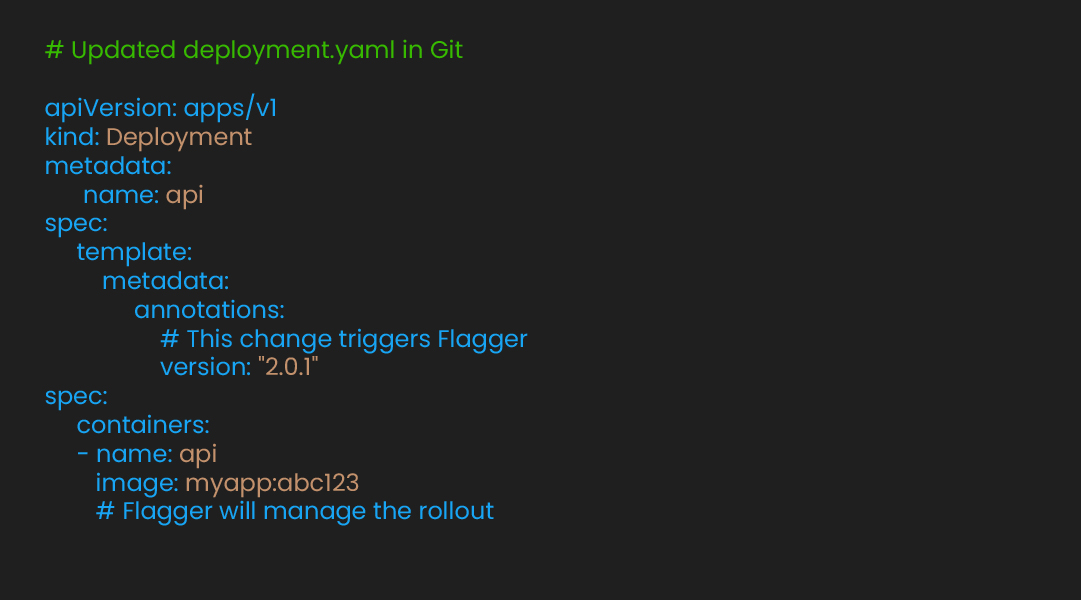
With progressive delivery catching bad releases early, you can now focus on how the platform reacts to load. Safe, fast deployments clear the way to tune scaling behavior aggressively when traffic spikes.
With fast deployments in place, we tune the platform for scaling. Default Kubernetes scaling may react slowly because it relies on trailing metrics and conservative policies.
Before we change autoscaling, see why Kubernetes’ behavior often lags during sudden spikes. Consider this scenario: An API normally handles moderate traffic across a small number of pods. When traffic suddenly increases significantly, the default HPA behavior follows a conservative pattern:
This measured approach may not match rapid traffic changes.
To scale the application better, feed traffic metrics into Kubernetes so it scales on demand, not just CPU. The solution involves three components working together:
First, instrument applications to expose relevant metrics:

Deploy Prometheus to collect these metrics: 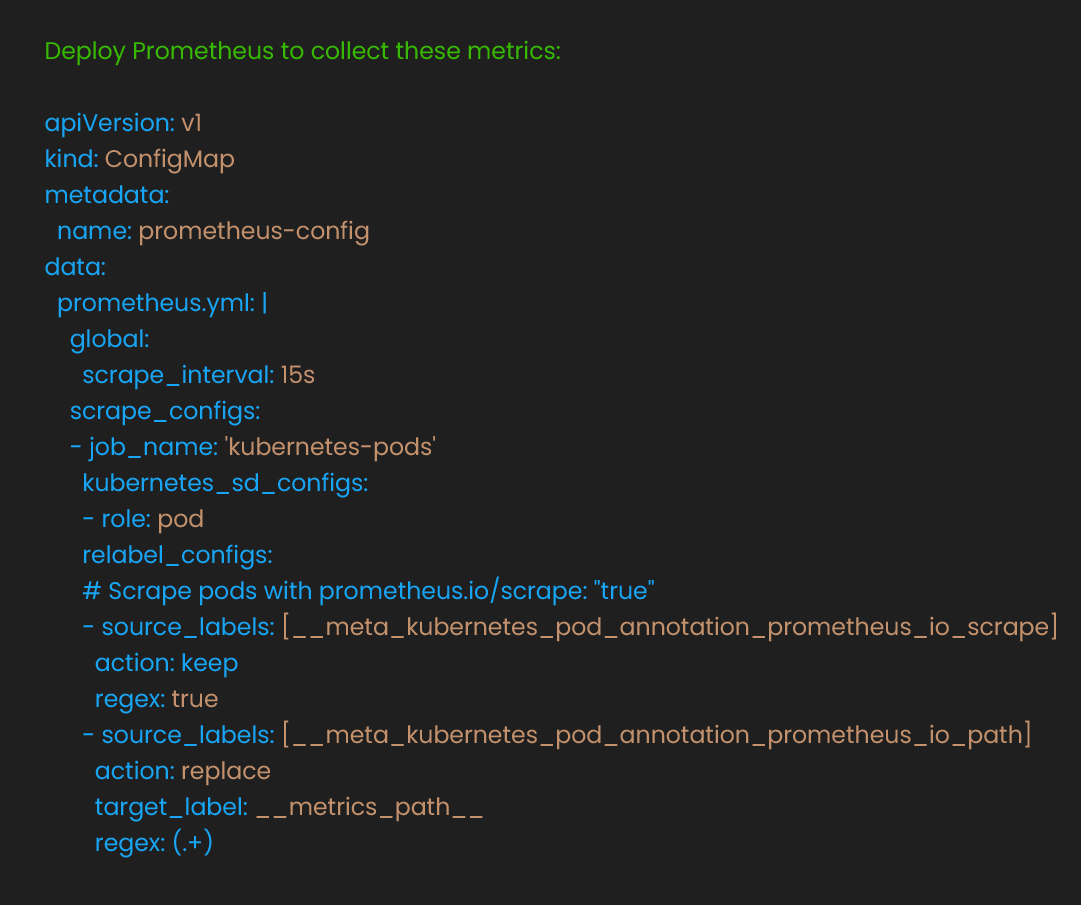
Only expose metrics you’ll actually use for scaling decisions. Each metric increases Prometheus storage and query load.
With metrics flowing, we tune the Horizontal Pod Scaler (HPA) for faster, larger steps. To configure HPA to scale based on request rate rather than just CPU:
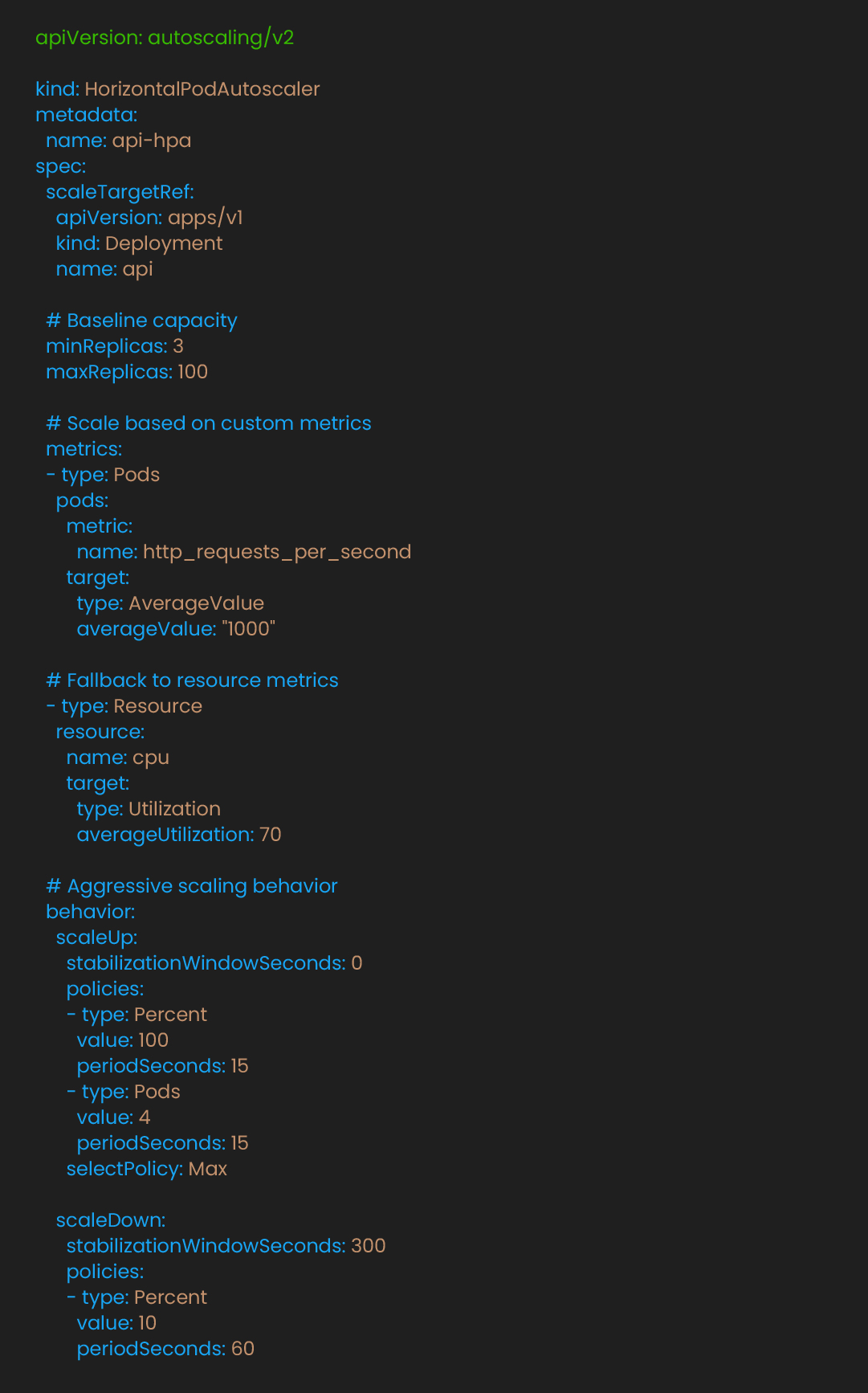
This configuration modifies scaling behavior significantly. The stabilizationWindowSeconds: 0 removes the waiting period for scale-up decisions. The policies allow for more aggressive scaling when needed by either doubling the pod count or adding multiple pods per evaluation period. This enables faster response to traffic changes compared to default behavior.
Pods that scale need nodes to land on; align node growth so upstream scale is not throttled, and cost stays sane. Pods require nodes to run on. Cluster Autoscaler adds nodes when pods can’t be scheduled:
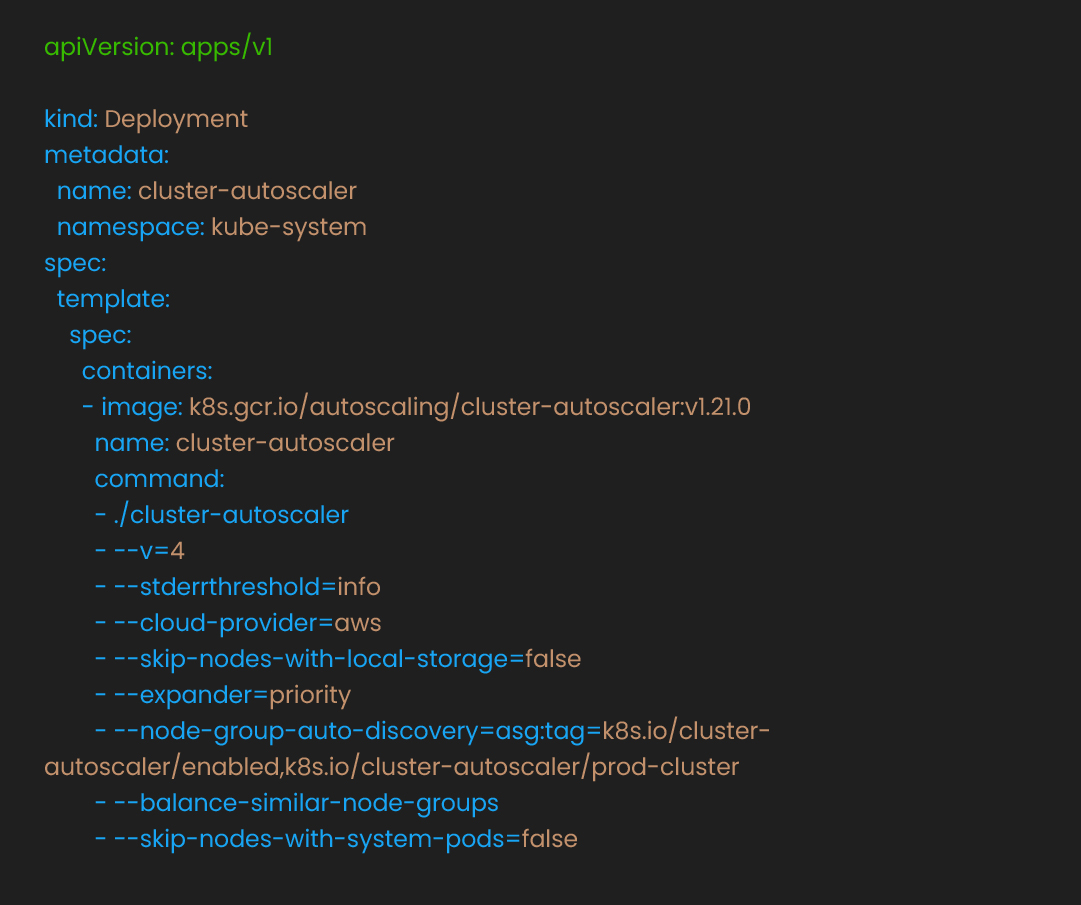
Configure node groups with different instance types:

This prioritizes smaller, less expensive instances first, scaling to larger instances as needed. This approach can help optimize costs while maintaining scaling flexibility. As clusters grow and you add services and nodes, the blast radius widens. Next, lock down traffic paths, runtime privileges, and secrets so scale does not multiply risk.
For teams exploring Kubernetes orchestration services, security often gets delayed. A layered approach implements defense-in-depth security that operates automatically.
Kubernetes allows all pod-to-pod communication by default. In a compromised scenario, an attacker gaining access to one component might access others. So, our first line of defense would be to restrict pod-to-pod paths. Network policies create micro segmentation:
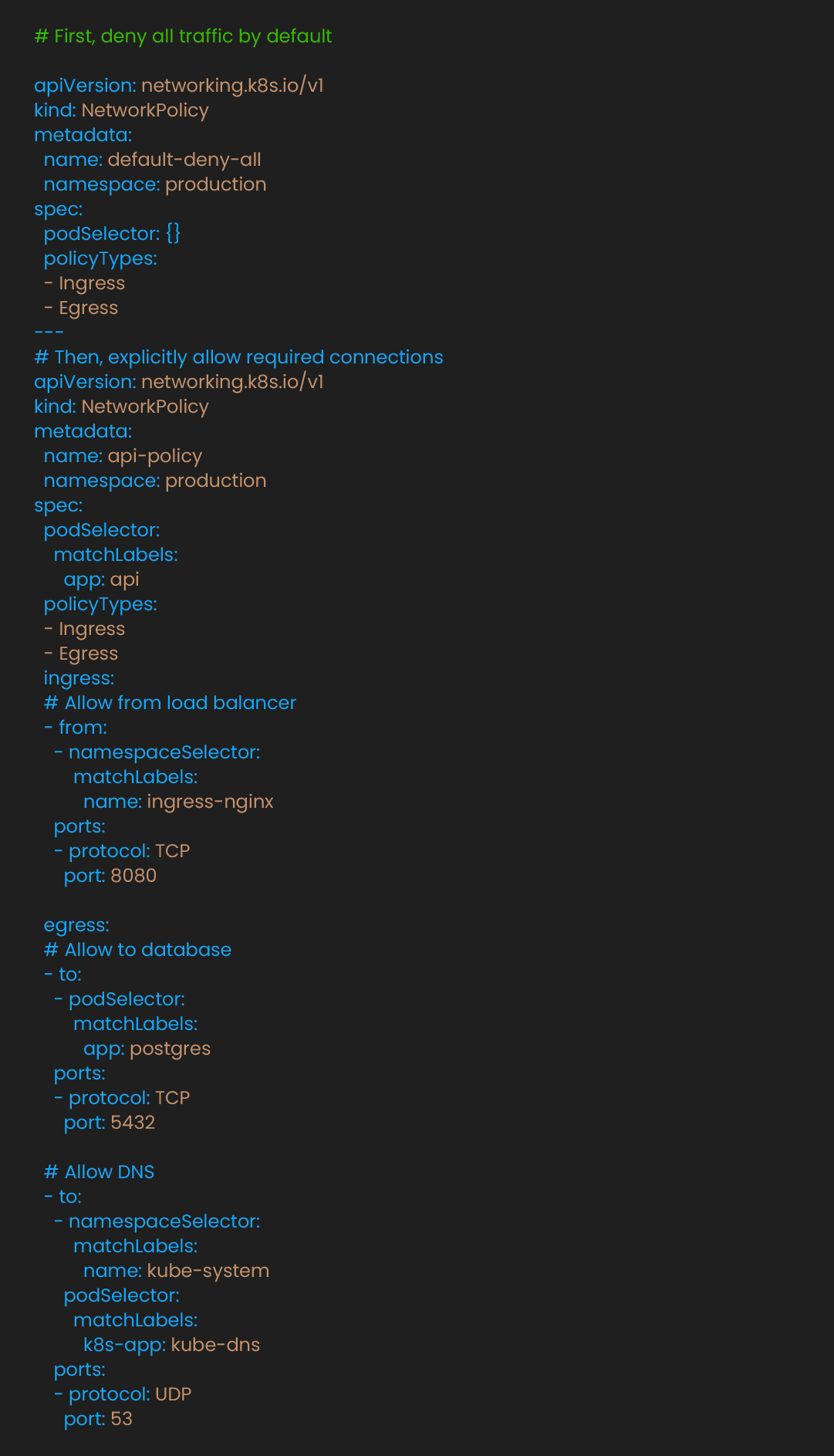
This configuration implements zero-trust networking. API pods accept connections only from specified sources and can only connect to explicitly allowed destinations. Combined with namespace boundaries and ingress, this limits potential damage from compromised components.
The next step is to lock down pod privileges and runtime posture; privilege boundaries shrink the breach blast radius. Containers with elevated privileges create security risks. Kubernetes Pod Security Standards (PSS) enforce secure configurations. Choose your security based on your environment:
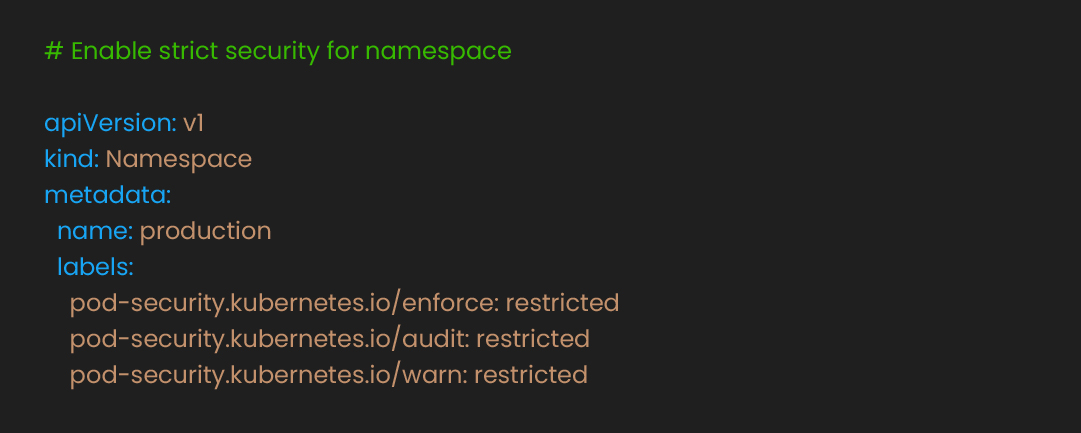
Update deployments to meet restricted standards:
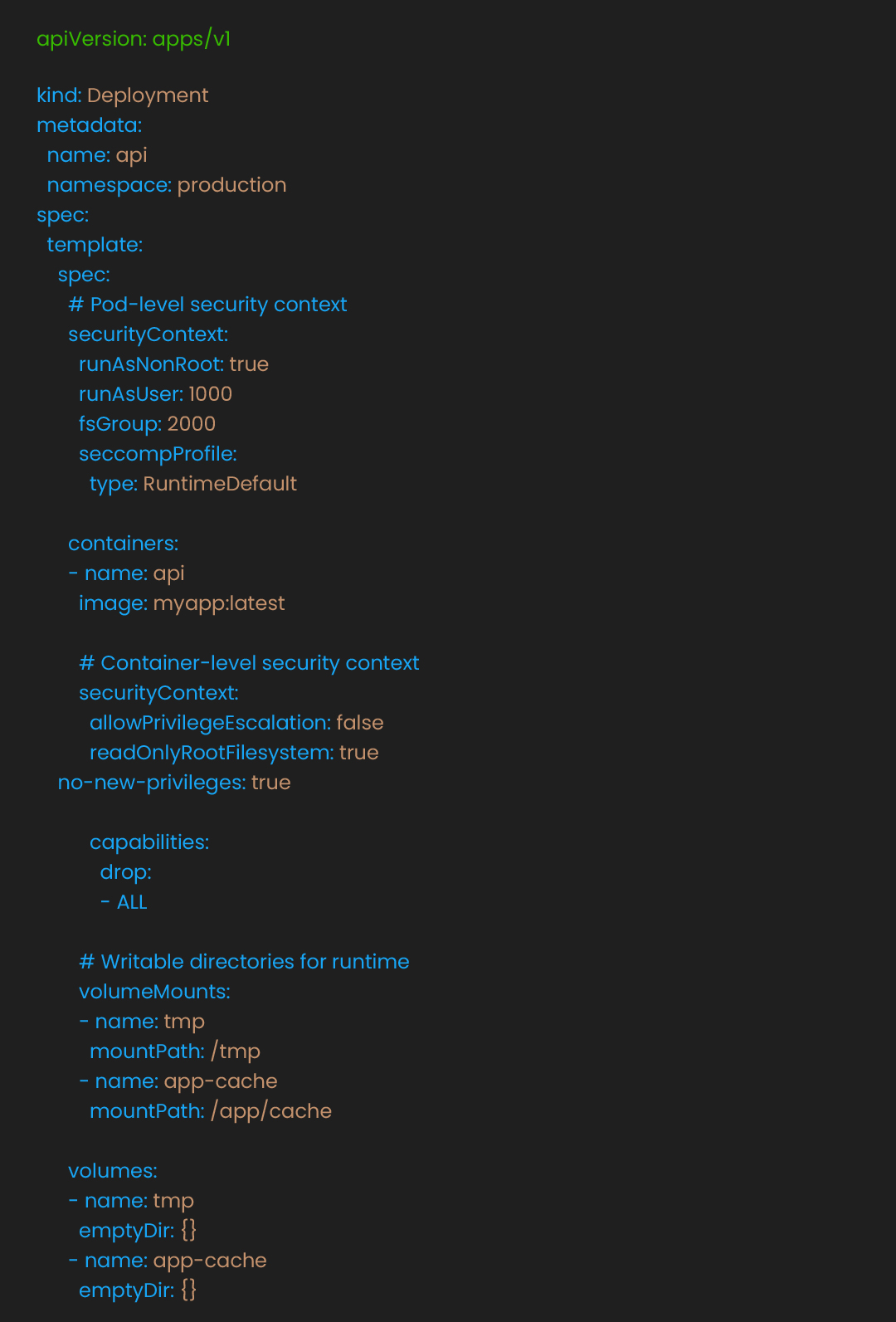
These settings help prevent privilege escalation and filesystem modifications. Applications must explicitly declare writable directories, limiting potential attack vectors.
Credentials and keys are high‑value targets; managing secrets well is central to Kubernetes security. Sealed Secrets addresses managing secrets for scalable containerized applications:

Only the Sealed Secrets controller in your cluster can decrypt this, maintaining security even if the Git repository is compromised.
Tools: Falco, AppArmor, SELinux, seccomp

In Pod spec:

Tooling: Kubernetes RBAC, OPA Gatekeeper, Azure AD/GCP IAM/IAM Roles for Service Accounts (IRSA)

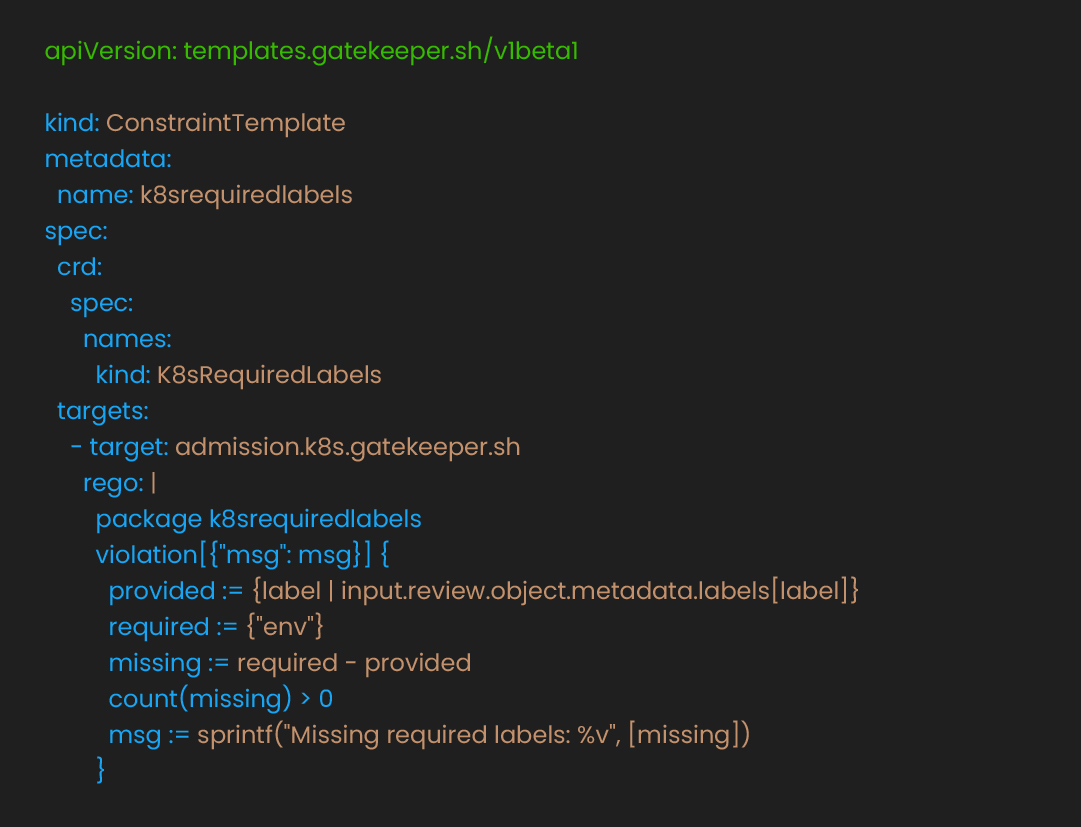
Tools: Snyk, Trivy, Cosign, Kyverno, Sigstore



Tools: Kubernetes Audit Logs, Promtail + Loki + Grafana, AWS/GCP/Azure logging
In kube-apiserver config:


Use Promtail + Loki, or forward audit logs to SIEM for alerts on policy violations.

Based on working with numerous container deployment for enterprises, this sequence minimizes risk while maximizing value:
Track rollout time, failed deploys caught, mean p95 latency under load, and number of namespaces under policy to measure progress.
Consider professional orchestration consulting services when:
These patterns provide a foundation, but every organization has unique requirements. Understanding the 4 key benefits of implementing Kubernetes in modern DevOps helps align architectural decisions with business objectives.
Production-ready Kubernetes requires implementing the right patterns in the right order, because each architectural decision enables the next one. Speed, scale, and security are interconnected capabilities that must evolve together to create platforms that accelerate rather than constrain business growth.
Understanding this principle and executing it are different challenges. This guide provided the blueprints and sequence. But the difference between knowing these patterns and running them in production is measured in incidents, not features.
This gap between theory and execution is where experience compounds. When you want to move from principles to execution across many services, outside leverage helps. Our containerization and orchestration service team works with your engineers to map speed, scale, and security gaps, implement priority patterns, to make your platform production ready not a production incident.
